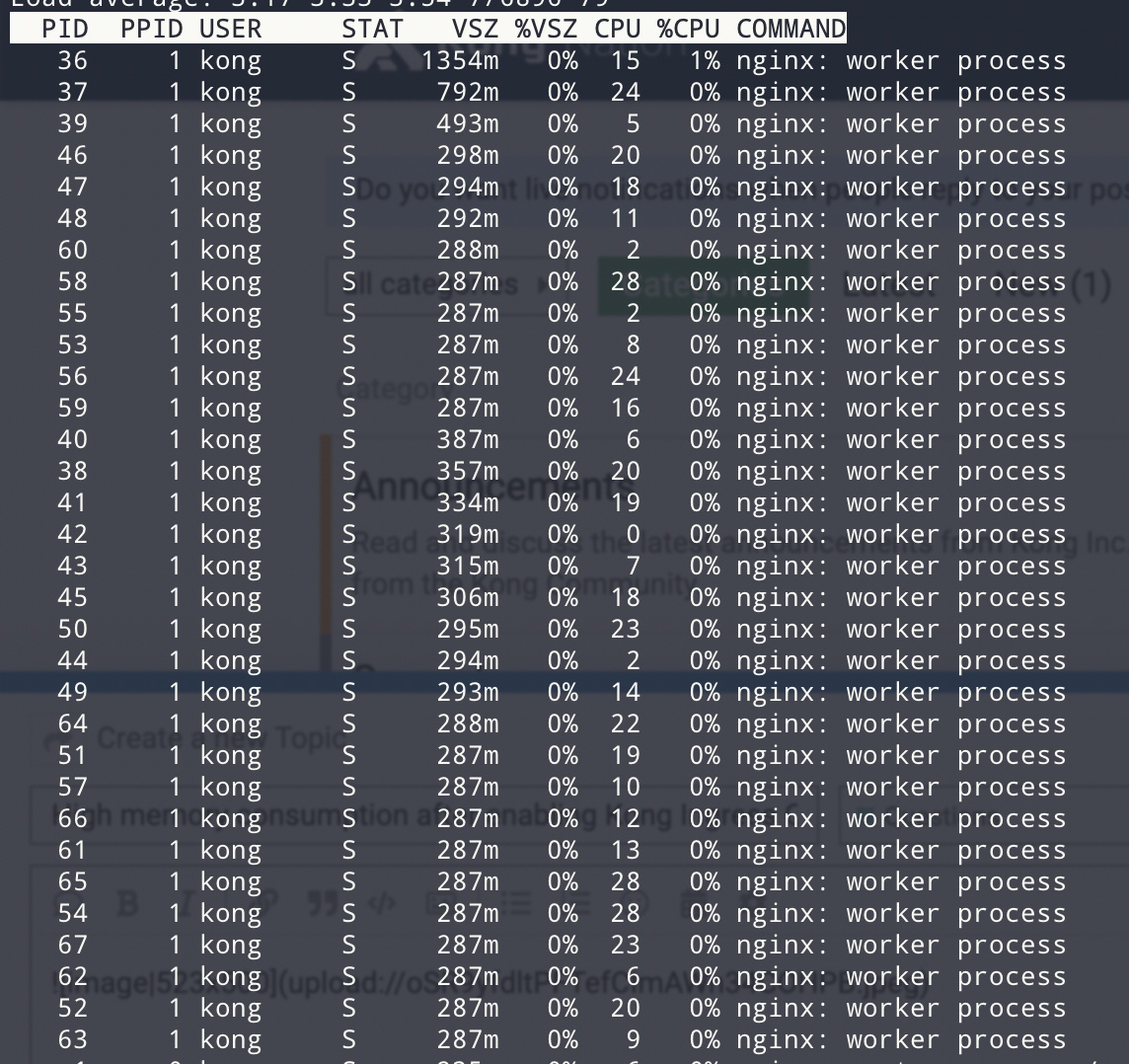
We recently introduced Kong Ingress Controller into our dev env and it works fine. However, we noticed a much higher memory consumption on the kong pods and especially abnormal memory usage on the Nginx worker processes.
The kong which remains at version 1.1.2 without Kong Ingress Controller consumes ~300mb memory per worker process while handling much higher throughput.
However, the kong proxy pods with Kong Ingress Controller as control pods (kong version 1.5.1 and KIC version 0.7.1) consume much higher memory per worker process:
It seems like you are running Kong on a machine withe many cores.
Please set the number of worker processes to a lower number using the environment variable KONG_NGINX_WORKER_PROCESSES="1". The correct number of workers depends on the workload. Typically 2-4 is more than enough.
Hi @hbagdi,
Thank you for your reply! I understood that setting the worker_processes to a smaller number will help, but I still have 2 questions:
Why the memory consumption per worker process is raised by ~3x for kong with kong ingress controller? Is it related to the lua cache on workers? I didn’t see much difference when I check the mertics kong_memory_workers_lua_vms_bytes.
May I ask why did you say “Typically 2-4 is more than enough”? I didn’t find much information on how this number should be determined. Do you mind shedding light on this?
Please upgrade to 1.4.2 or later. The version you are using has a memory leak. This is the PR
In virtualized environments, a process inside a container can still look at OS-level info, like memory and CPUs. But it doesn’t mean that the process has sole control over these resources. With Kubernetes, you will likely have other pods running on the same host as well. If you are running Kong on a dedicated box, then a higher worker count will get your something. Also, with more worker threads, Kong’s performance, in some use-cases, will not increase linearly because the lock contention between the parallel worker processes will increase.
Going one level below, it is not necessary that every vCPU in a VM maps to a physical core. Cloud providers often do over-provisioning and in such scenarios, having a Linux process for each vCPU makes less and less sense, since each of those process eventually needs to be scheduled onto a physical CPU.