@gkn103 I ran your question through our developer.konghq.com AI chat assistant. Please check the answer for accuracy with tests. I hope this is helpful.
The behavior you’re seeing matches Kong’s default upstream timeout settings: 60 000 ms (60 s) for connect, read, and write timeouts at the Service level. [Proxying timeouts]
Key points from the docs:
-
By default, a Gateway Service has:
-
These timeouts are configured on the Service, not the Route. [Gateway Service timeouts]
-
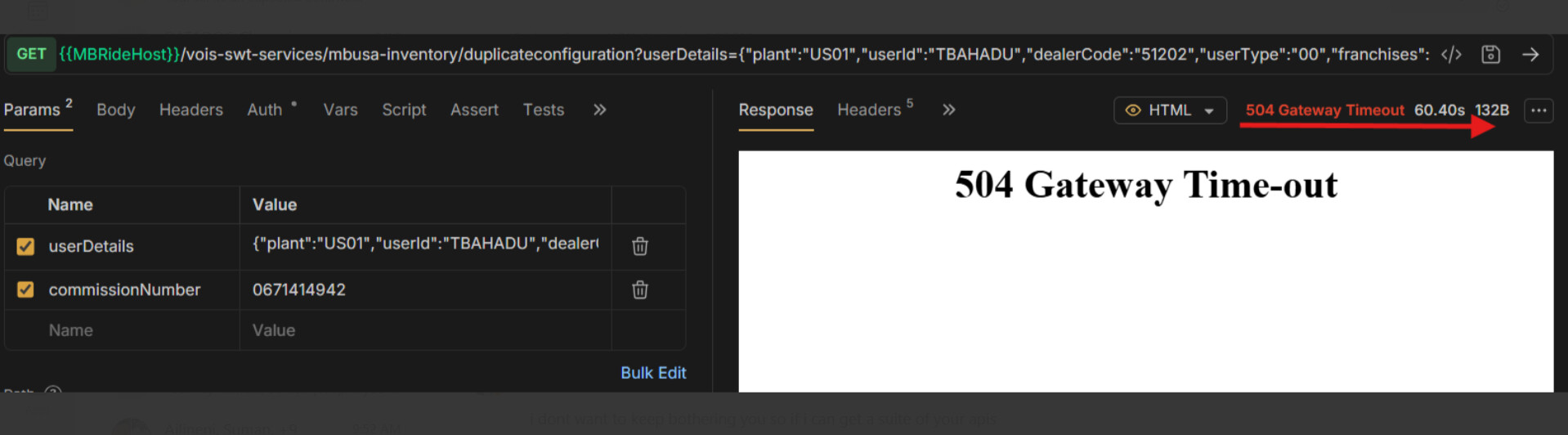
If the upstream takes longer than the configured read_timeout, Kong returns 504 Gateway Time-out. [Gateway Service timeouts]
-
The 499 codes in Kong logs indicate the client closed the connection before Kong finished sending the response (often due to a client-side timeout, e.g. a load balancer or Postman timeout). [499 explanation]
Where the 60 s timeout is coming from
Most likely:
-
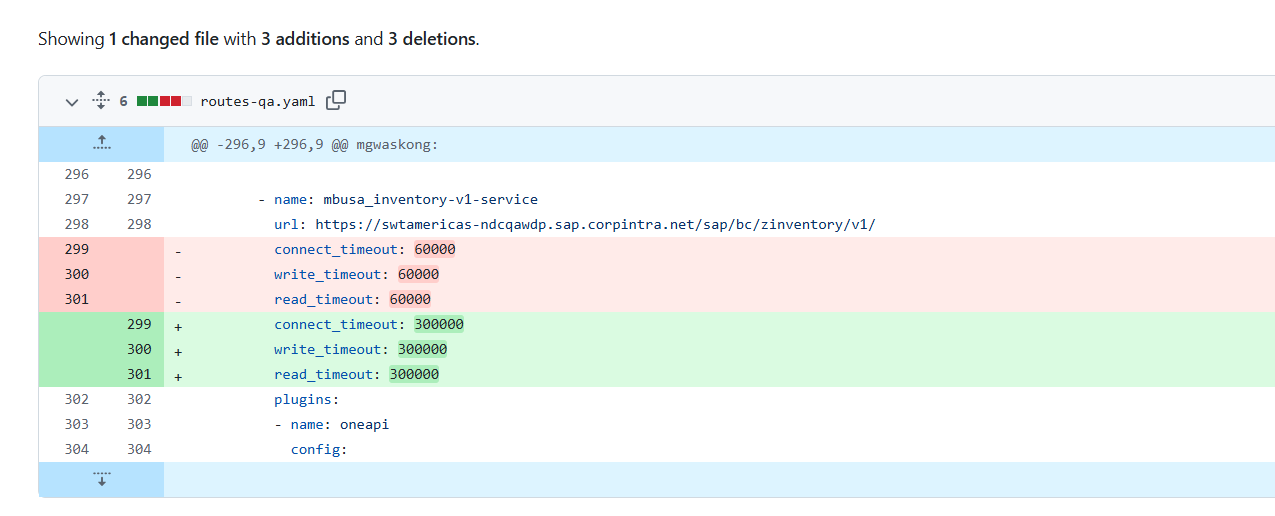
Service-level timeouts are still at their defaults (60 000 ms).
-
You changed a timeout “in the route file”, but Route entities do not control upstream timeouts by default; they are controlled by:
-
Service fields (connect_timeout, read_timeout, write_timeout), or [Proxying timeouts]
-
The Upstream Timeout plugin, if you are using it, which overrides Service-level timeouts. [Upstream Timeout]
How to increase the timeout
Pick one of these approaches (they can be combined, but you usually only need one):
1. Increase timeouts on the Service
Via Admin API (example):
curl -X PATCH http://<admin-host>:8001/services/mbusa_inventory-v1 \
--header "kong-admin-token: <TOKEN>" \
--data "read_timeout=180000" \
--data "write_timeout=180000" \
--data "connect_timeout=60000"
This sets a 180 s read/write timeout for that Service. [Proxying timeouts]
If you manage config with decK, you’d adjust the Service in kong.yaml and run deck gateway sync. [decK example]
2. If using Kubernetes Ingress
Set Service annotations (values in ms): [KIC connect-timeout; KIC read-timeout]
apiVersion: v1
kind: Service
metadata:
name: mbusa-inventory-v1
annotations:
konghq.com/connect-timeout: "60000"
konghq.com/read-timeout: "180000"
konghq.com/write-timeout: "180000"
3. If using the Upstream Timeout plugin
This plugin overrides Service-level timeouts. [Upstream Timeout; Plugin config]
Example on a Route:
curl -X POST http://<admin-host>:8001/routes/<route_id>/plugins \
--header "kong-admin-token: <TOKEN>" \
--data "name=upstream-timeout" \
--data "config.read_timeout=180000" \
--data "config.write_timeout=180000" \
--data "config.connect_timeout=60000"
Also check retries
If retries is > 0, Kong can retry on timeout, so the total observed latency can exceed the configured timeout (e.g. 60 s timeout × multiple retries). [Kong proxy latency]
You may want to:
curl -X PATCH http://<admin-host>:8001/services/mbusa_inventory-v1 \
--data "retries=0"
Why you see both 504 and 499
After increasing the Service (or plugin) timeouts and ensuring any client/LB in front of Kong also has a higher timeout than 60 s, calls that take > 60 s upstream should stop failing at 60 s.